Disclaimer: This is more of a note for me, coming from my experience during my journey, and I’ll update it from time to time.
Table of Contents:
- Business Requirements
- Problem Identification
- Data Processing
- Baseline Models
- Model Training and Evaluation
- Regularization and Ensembling
- Interpretation and Presentation
Business Requirements
The first step is to understand the business requirements and the nature of available data. Most machine learning models are trained to serve a real-world use case. It’s necessary to understand the big picture and know what approach should be taken to solve the problem.
The following questions can be helpful in this stage:
- What is the business problem that you’re going to solve using machine learning?
- Why are we interested in solving this problem using machine learning?
- How is the problem currently solved without machine learning?
- Who will use the result of the model, and how does it fit into other business processes?
- How much historical data do we have, and how was it collected?
- What feature does the data have, and does it contain the value we want to predict?
- What are some known issues with the data?
- Can we look at some sample rows of the data? How do they represent the whole dataset?
- Where and how can we access the data?
The main goal is to gather as much information and data as possible about the problem to understand whether it’s feasible to solve it using machine learning.
Problem Identification
In this step, we need to understand the problem’s category.
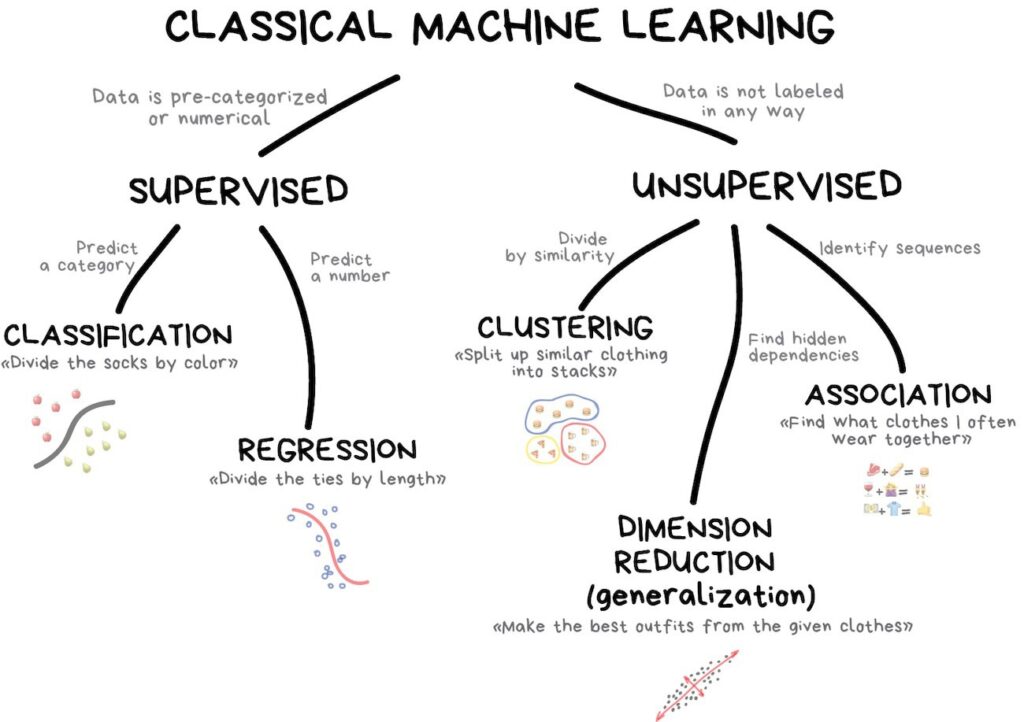
Data Processing
What should be done in this step?
- Study the distribution of individual columns (uniform, normal, exponential)
- Detect anomalies or errors in the data (e.g., missing/incorrect values)
- Study the relationship of the target column with other columns (linear, non-linear, etc.)
- Gather insights about the problem and the datasets
- Processing data and feature engineering
Finally, after going through all the steps above, data is ready to be divided to “train”, “validation”, and “test” datasets to go for training and evaluating a model.
Baseline Models
In this step, a quick base model will trained. Not all columns are necessary to train this model. This will be used to see if the trained model in the next part is working any better than simple, quick baseline models.
Model Training and Evaluation

Some of the models should be used to train based on the problem. This cheat sheet from SciKit Learn could be useful.
An Excel sheet should be created to record the results of all experiments, such as the model’s name, score, hyperparameters, error, and any other required details.
Regularization and Ensembling
In this step, we should apply strategies to improve the performance of models. This includes all of the below approaches:
- Gathering more data
- Feature engineering
- Tune models
- Explore models to gather insights and ideas to improve/fix them
- Combine models’ results or train a new proper model based on the previous results
Interpretation and Presentation
How to present it?
- Create a presentation for non-technical stakeholders
- Understand your audience – figure out what they care about most
- Avoid showing any code or technical jargon, including visualizations
- Focus on metrics that are relevant to the business
- Talk about feature importance and how to interpret results
- Explain the strengths and limitations of the model
- Explain how the model can be improved over time